Nota Runs VLA Robotics Model in Real Time on Qualcomm Edge AI Hardware
Nota demonstrated real-time operation of a vision-language-action robotics model on Qualcomm Dragonwing edge AI hardware. The company reduced the model action-head processing time from 218 milliseconds to 31 milliseconds while keeping task success nearly unchanged. The demo points to a path for physical AI systems that can run closer to robots rather than relying mainly on GPU servers or cloud infrastructure.
Nota runs a VLA robotics model in real time on Qualcomm edge AI hardware
South Korean AI optimization company Nota says it has demonstrated real-time operation of a vision-language-action model on an edge AI device, showing how physical AI workloads could move closer to robots and autonomous systems.
The company presented the work at Embedded Vision Summit 2026 in Santa Clara, California.
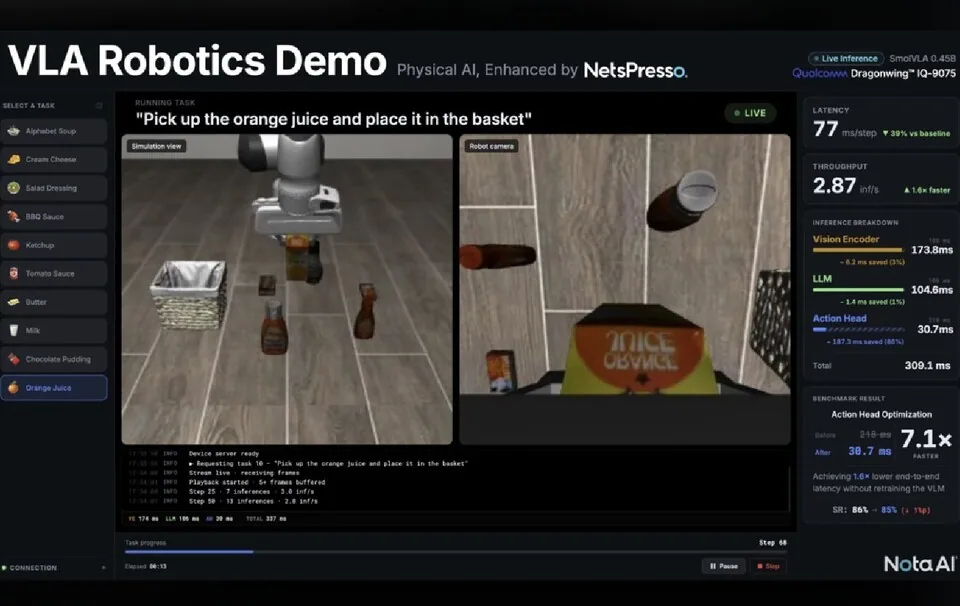
The demo used Qualcomm's Dragonwing IQ-9075 edge AI device to run SmolVLA 0.45B, a robotics VLA model that connects visual perception, language understanding and action generation.
VLA models are important for physical AI because they allow a system to see its environment, interpret natural-language instructions and turn those inputs into movement.
But that combined workload is computationally heavy, and many VLA deployments still depend on GPU servers or cloud infrastructure rather than embedded devices.
Selective optimization instead of full compression
Nota said its approach did not compress the entire model.
It kept the visual perception and language understanding stages intact and focused optimization on the action head, the part that generates robot movement commands.
The company used two techniques: real-time inference optimization to reduce repeated computation, and NPU-based graph optimization to redesign the computation flow for Qualcomm's edge AI execution environment.
The result was a sharp reduction in action-head processing time from 218 milliseconds to 31 milliseconds.
That is an 85.8% decrease and up to a sevenfold speed improvement.
Total inference time also fell from 505 milliseconds to 310 milliseconds, while the task success rate moved only slightly from 86% to 85%.
Why it matters for physical AI
At the summit, visitors selected items and the optimized VLA model recognized them in real time, then directed a robot arm to place them in a basket.
Nota said the demonstration was not a replayed video or fixed scenario; the AI made decisions on site according to each visitor's choice.
The result supports Nota's argument that industrial physical AI will need models that run quickly and reliably on edge devices.
The company links the work to demand across on-device AI, data centers and physical AI.
Nota reported first-quarter 2026 consolidated revenue of 3.58 billion won, compared with about 67 million won a year earlier.
Its order backlog stood at about 12.1 billion won at the end of the quarter.
Chief executive Chae Myung-soo said the VLA optimization shows that Nota's technology can become a core foundation for physical AI adoption in industrial settings.
Summary version for Medium
Nota Runs VLA Robotics Model in Real Time on Qualcomm Edge AI Hardware
What the announcement means beyond the headline
Quick Summary: Nota demonstrated real-time operation of a vision-language-action robotics model on Qualcomm Dragonwing edge AI hardware. The company reduced the model action-head processing time from 218 milliseconds to 31 milliseconds while keeping task success nearly unchanged.
Nota runs a VLA robotics model in real time on Qualcomm edge AI hardware
South Korean AI optimization company Nota says it has demonstrated real-time operation of a vision-language-action model on an edge AI device, showing how physical AI workloads could move closer to robots and autonomous systems. The company presented the work at Embedded Vision Summit 2026 in Santa Clara, California.
Selective optimization instead of full compression
Nota said its approach did not compress the entire model.
- Point 1: The central topic is ai, with the announcement framed around concrete operating detail.
- Point 2: It kept the visual perception and language understanding stages intact and focused optimization on the action head, the part that generates robot movement commands.
The important shift is not the AI label, but the operating boundary it creates for teams.
Why it matters for physical AI
At the summit, visitors selected items and the optimized VLA model recognized them in real time, then directed a robot arm to place them in a basket. Nota said the demonstration was not a replayed video or fixed scenario; the AI made decisions on site according to each visitor's choice.
Read the Full Deep Dive
Want to explore the complete technical analysis, enterprise trade-offs, and detailed metrics?
Read the full article originally published at SendTech Times