Grep تضيف وكيل LLM إلى Monito مع تحول مراقبة الاختبارات نحو مراجعة السياق
قالت Grep إن منتج Monito لمراقبة الاختبارات عبر الإنترنت يستخدم الآن وكيل LLM لتحليل السياق حول الأحداث المشتبه بها. وذكرت الشركة اختبارات داخلية أظهرت تقليص وقت المراجعة بعد الاختبار بأكثر من 30% وخفض التنبيهات الخاطئة بنحو 20%. وتبقى القضية الرئيسية هي ما إذا كانت المراقبة المعتمدة على الوكلاء تستطيع تحسين الكفاءة مع الحفاظ على الحكم البشري النهائي وعدالة المرشحين.
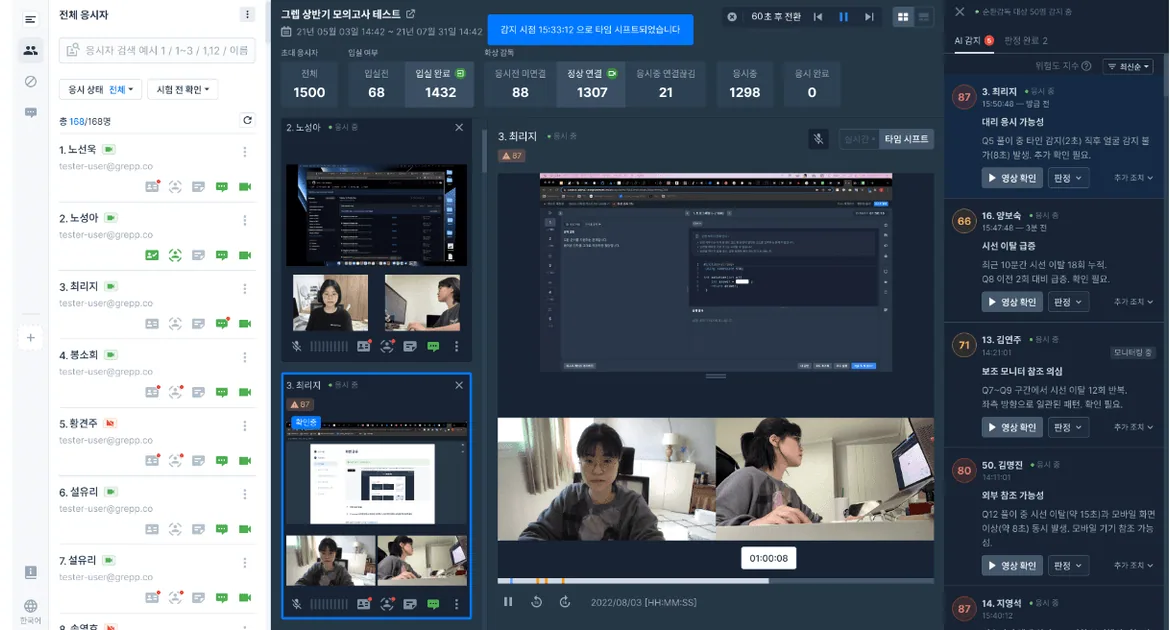
Grep تنقل مراقبة الاختبارات من الرصد إلى فهم السياق
قالت Grep إنها أضافت نظام وكلاء إلى Monito، منتجها لمراقبة الاختبارات عبر الإنترنت، بهدف تحسين دقة رصد حالات الاشتباه في الغش.
يعتمد المنتج بالفعل على وظائف مدعومة بالذكاء الاصطناعي مثل تتبع النظر، وتوثيق الوجه، ومنع نسخ الشاشة واستخدام شاشة مزدوجة، إضافة إلى مراقبة فورية بثلاث قنوات عبر كاميرا الويب والهاتف المحمول ومشاركة الشاشة. وذكر المصدر أن Monito أثبت توفيراً في تكاليف التشغيل يصل إلى 40% مقارنة بالمراقبة الحضورية.
الإشارة الجديدة هي الانتقال من رصد الأحداث البسيطة إلى تحليل السياق. وقالت Grep إن الأنظمة السابقة كانت تعتمد على تنبيهات مادية مثل خروج اليد من نطاق الشاشة، ما حد من الدقة. وأدخلت الشركة الآن وكيل LLM يراجع السياق المحيط بدلاً من الحكم على فعل واحد بمعزل عن غيره.
لماذا يهم ذلك
بالنسبة إلى مزودي تقنيات التعليم وفرق الاختبارات المؤسسية ومشغلي الشهادات، يشير الإعلان إلى حالة استخدام عملية لوكلاء الذكاء الاصطناعي: تقليل عبء المراجعة مع إبقاء الإنسان في حلقة القرار النهائي.
وقالت Grep إن الميزات الرئيسية تشمل ملخصات موقف تضيف سياقاً إلى نتائج رصد الذكاء الاصطناعي، ودرجة للغش تتيح للمشرفين فحص المرشحين الأعلى خطراً أولاً، والتنقل السريع إلى مقطع الفيديو ذي الصلة عند العثور على نشاط مشبوه. وقالت الشركة إن الوكيل يستطيع تلخيص الحالات المشتبه بها وسياقها في تقارير سردية، ما يسمح للمراقبين البشريين بمراجعة الحالات التي اختارها الذكاء الاصطناعي بدلاً من مراقبة كل الفيديو في الوقت الفعلي.
وبحسب اختبارات داخلية وردت في المصدر، قلل النهج وقت المراجعة بعد الاختبار بأكثر من 30% مقارنة بفحص تسجيلات الفيديو كاملة. وتظهر لوحة وكيل الذكاء الاصطناعي الجديدة في الجانب الأيمن من شاشة المشرف وتقدم نتائج التحليل في الوقت الفعلي.
المراجعة البشرية تبقى أساسية
يحرص المصدر على عرض الذكاء الاصطناعي كمساعد وليس كحكم نهائي. فقد أكدت Grep أن الذكاء الاصطناعي لا يتخذ القرار النهائي بشأن الغش. إنه يختار الظروف المشتبه بها ويبلغ عنها، بينما يجب أن يتخذ مشرف بشري القرار النهائي ضمن بنية الإنسان في الحلقة.
هذا التمييز مهم لأن أنظمة مراقبة الاختبارات تؤثر في عدالة الاختبار وثقة المرشحين. وقالت Grep إن النظام صمم بحيث لا يتضرر المتقدمون بحسن نية حتى إذا أنتج الذكاء الاصطناعي إنذاراً خاطئاً. وأظهرت الاختبارات الداخلية أيضاً أن التنبيهات الخاطئة انخفضت بنحو 20%.
ما يجب متابعته
ينبغي متابعة ما إذا كانت Grep تستطيع تحويل طبقة الوكيل إلى تحسينات موثوقة قابلة للقياس خارج الاختبارات الداخلية. وقالت الشركة إن جمع البيانات واستخدامها لتدريب نماذج الذكاء الاصطناعي يلتزمان بقانون حماية المعلومات الشخصية والقواعد ذات الصلة، مع إزالة تعريف بيانات الفيديو بحيث لا يمكن التعرف على الوجوه والمعلومات الشخصية الحساسة الأخرى.
مجال التطوير التالي هو مراقبة الاختبارات بالذكاء الاصطناعي متعدد الوسائط. وتخطط Grep لتطوير تقنية تدمج الفيديو والصوت وسجلات البيئة، ولتطوير الوكيل بحيث يحلل بيانات سلوكية إضافية مثل مسارات حركة الفأرة وأنماط الكتابة على لوحة المفاتيح.
Summary version for Medium
Grep Adds LLM Agent To Monito As Online Proctoring Shifts Toward Context Review
What the announcement means beyond the headline
Quick Summary: Grep said its Monito online proctoring product now uses an LLM agent to analyze context around suspected cheating events. The company cited internal tests showing more than 30 percent shorter post-exam review time and nearly 20 percent fewer false alerts.
Grep Moves Proctoring From Detection To Context
Grep said it has added an agent system to Monito, its online exam proctoring product, in an effort to improve the accuracy of suspected cheating detection. The product already uses AI-based functions such as gaze tracking, face authentication, prevention of screen duplication and dual-monitor use, as well as three-channel real-time monitoring through webcam, mobile and screen sharing.
Why It Matters
For education technology providers, corporate testing teams and certification operators, the announcement points to a practical use case for AI agents: reducing review workload while keeping humans in the final decision loop.
- Point 1: The central topic is ai, with the announcement framed around concrete operating detail.
- Point 2: Grep said the main features are situation summaries that add context to AI detection results, a cheating score that lets supervisors check higher-risk candidates first, and fast...
Stateful isolation is becoming a first-class cloud primitive, not just an implementation detail.
Human Review Remains Central
The source is careful to frame the AI as an assistant, not the final judge. Grep emphasized that AI does not make the final cheating determination.
Read the Full Deep Dive
Want to explore the complete technical analysis, enterprise trade-offs, and detailed metrics?
Read the full article originally published at SendTech Times