X-Square WALL-WM Points Robotics AI Toward Event-Level Planning
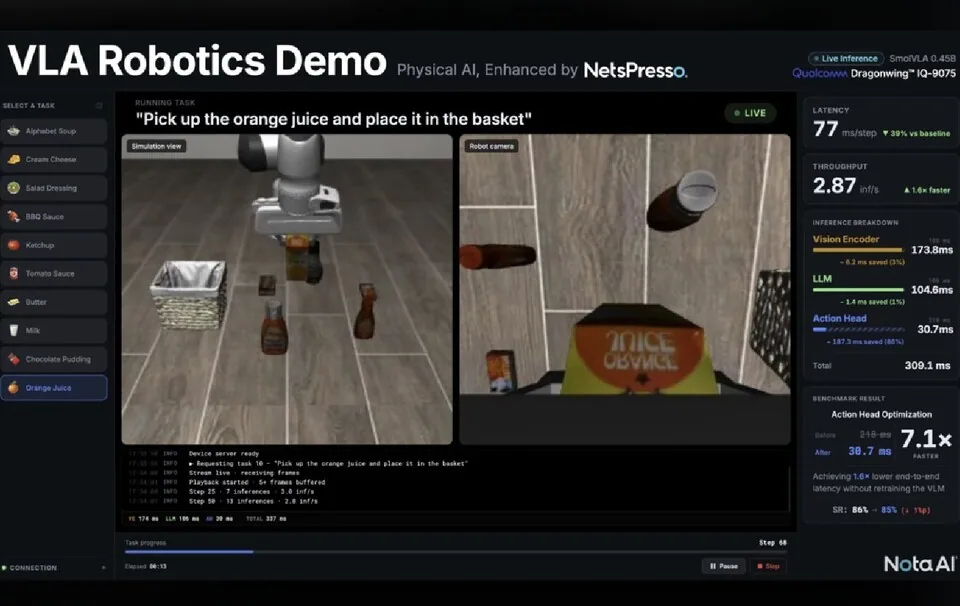
X-Square Robot released WALL-WM, an embodied AI world model that predicts semantic events rather than fixed motion frames. The company says the approach helps robots focus on task objectives such as grasping an object instead of memorizing pixel-level movement sequences. Reported benchmarks show stronger motion quality, semantic consistency, physical plausibility and task completion than several comparison models.

X-Square Robot is trying to change how embodied AI systems plan physical tasks.
Its new WALL-WM model moves prediction away from short fixed frames and toward event-level understanding, a shift aimed at making robots less dependent on memorized motion sequences.
The Chinese company, known for its GreatWall robotic foundation models, says WALL-WM is an event-level prediction world model for embodied intelligence.
The claim matters because robot control still struggles when a task looks familiar but the object, surface, or timing changes.
The Architecture Signal
Most vision-language-action systems predict movement in small time slices.
In the source example, a model may estimate where a robot hand should be at 0.1 seconds and 0.2 seconds, rather than reasoning directly about the target outcome.
WALL-WM reframes that problem.
Instead of predicting the next frame, it predicts a semantic event such as the moment of grasping an object, then generates the actions needed to reach that state.
The approach is designed to help the robot focus on task intent rather than pixel-by-pixel motion patterns.
Why Event Prediction Matters
The core promise is generalization.
A frame-based model can break when the cup, table, or timing changes because it has learned a narrow motion sequence.
An event-based model should have a better chance of adapting because the event, not the exact scene, becomes the anchor.
That is important for embodied AI because physical environments are variable.
Contact states, object positions, timing precision, and small perturbations can all change the outcome of a manipulation task.
Technical Proof Points
The WALL-WM paper identifies a mismatch among text, vision, and action data.
Text carries high-level intent, vision changes continuously, and action is constrained by physics and contact.
X-Square Robot says its answer is a three-layer system: an event instruction entry layer, a core event prediction layer using distributed Muon optimization, and a multi-event packing strategy that trains several events inside one long sequence.
The company reports stronger results than Wan2.1-14B and Open-Sora 2.0 on embodied video generation benchmarks, and higher task completion than Pi0.5 and DreamZero on the Core15 L1 robot benchmark.
What To Watch
The next test is whether WALL-WM can move from benchmark performance to reliable robot behavior outside controlled demonstrations.
The source points to better motion quality, semantic consistency, physical plausibility, reasoning, dexterous manipulation, and generalization scores.
For robotics developers, the larger signal is that embodied AI is moving from visual imitation toward goal-level planning.
If event-centric world models hold up in deployment, they could become a more practical foundation for robots that need to handle changing objects and environments.
Summary version for Medium
X-Square WALL-WM Points Robotics AI Toward Event-Level Planning
What the announcement means beyond the headline
Quick Summary: X-Square Robot released WALL-WM, an embodied AI world model that predicts semantic events rather than fixed motion frames. The company says the approach helps robots focus on task objectives such as grasping an object instead of memorizing pixel-level movement sequences.
The Architecture Signal
Most vision-language-action systems predict movement in small time slices. In the source example, a model may estimate where a robot hand should be at 0.1 seconds and 0.2 seconds, rather than reasoning directly about the target outcome.
Why Event Prediction Matters
The core promise is generalization.
- Point 1: The central topic is embodied AI, with the announcement framed around concrete operating detail.
- Point 2: A frame-based model can break when the cup, table, or timing changes because it has learned a narrow motion sequence.
The important shift is not the AI label, but the operating boundary it creates for teams.
Technical Proof Points
The WALL-WM paper identifies a mismatch among text, vision, and action data. Text carries high-level intent, vision changes continuously, and action is constrained by physics and contact.
Read the Full Deep Dive
Want to explore the complete technical analysis, enterprise trade-offs, and detailed metrics?
Read the full article originally published at SendTech Times