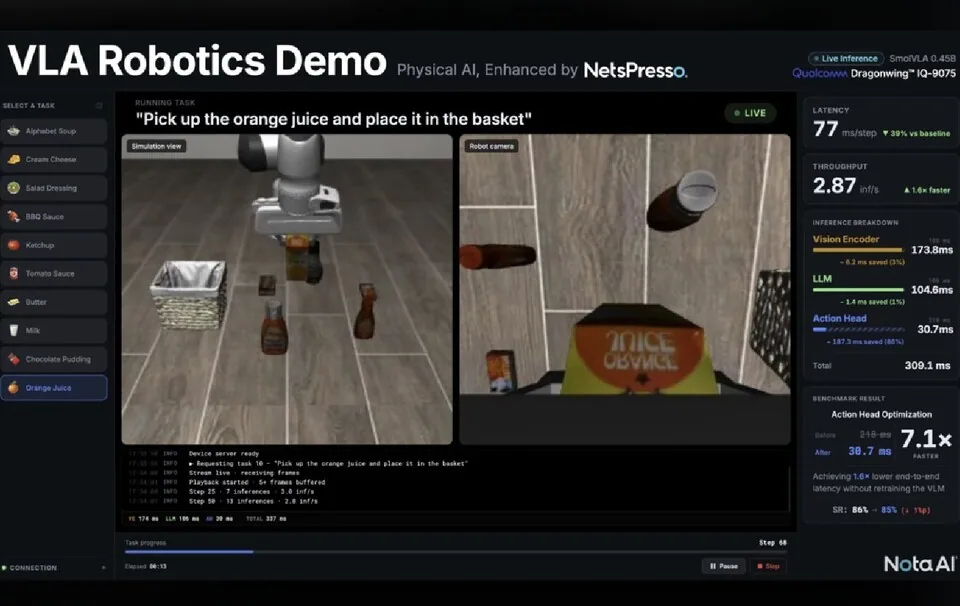
نموذج WALL-WM من X-Square يدفع ذكاء الروبوتات نحو التخطيط على مستوى الحدث
أطلقت X-Square Robot نموذج WALL-WM للذكاء الاصطناعي المجسد، وهو نموذج عالم يتنبأ بالأحداث الدلالية بدلا من الإطارات الحركية الثابتة. وتقول الشركة إن النهج يساعد الروبوتات على فهم هدف المهمة مثل الإمساك بجسم بدلا من حفظ تسلسلات حركة دقيقة. وتشير نتائج الاختبارات إلى أداء أقوى في جودة الحركة والاتساق الدلالي والمعقولية الفيزيائية وإنجاز المهام.

تحاول X-Square Robot تغيير الطريقة التي تخطط بها أنظمة الذكاء الاصطناعي المجسد للمهام الفيزيائية. وينقل نموذجها الجديد WALL-WM التنبؤ من الإطارات الزمنية القصيرة الثابتة إلى فهم الأحداث، في تحول يستهدف جعل الروبوتات أقل اعتمادا على تسلسلات الحركة المحفوظة.
تقول الشركة الصينية، المعروفة بنماذج GreatWall الأساسية للروبوتات، إن WALL-WM هو نموذج عالم يتنبأ على مستوى الحدث للذكاء المجسد. وتبرز أهمية هذا الادعاء لأن التحكم الروبوتي ما زال يواجه صعوبة عندما تبدو المهمة مألوفة لكن يتغير الجسم أو السطح أو التوقيت.
إشارة البنية
تتنبأ معظم أنظمة الرؤية واللغة والحركة بالحركة ضمن شرائح زمنية صغيرة. وفي مثال المصدر، قد يقدر النموذج أين يجب أن تكون يد الروبوت بعد 0.1 ثانية و0.2 ثانية، بدلا من التفكير مباشرة في النتيجة المستهدفة.
يعيد WALL-WM صياغة هذه المشكلة. فبدلا من التنبؤ بالإطار التالي، يتنبأ بحدث دلالي مثل لحظة الإمساك بجسم، ثم يولد الأفعال اللازمة للوصول إلى تلك الحالة. وصمم النهج لمساعدة الروبوت على التركيز على نية المهمة بدلا من أنماط الحركة المرتبطة بالبكسلات.
لماذا يهم التنبؤ بالحدث
الوعد الأساسي هو التعميم. يمكن أن يتعطل النموذج القائم على الإطارات إذا تغير الكوب أو الطاولة أو التوقيت لأنه تعلم تسلسل حركة ضيقا. أما النموذج القائم على الحدث فيفترض أن تكون لديه فرصة أفضل للتكيف لأن الحدث، لا المشهد الدقيق، يصبح نقطة الارتكاز.
هذا مهم للذكاء الاصطناعي المجسد لأن البيئات الفيزيائية متغيرة. فحالات التلامس، ومواقع الأشياء، ودقة التوقيت، والاضطرابات الصغيرة يمكن أن تغير جميعها نتيجة مهمة المناولة.
نقاط الإثبات التقنية
تحدد ورقة WALL-WM عدم توافق بين بيانات النص والرؤية والحركة. فالنص يحمل نية عالية المستوى، والرؤية تتغير باستمرار، والحركة مقيدة بالفيزياء والتلامس. وتقول X-Square Robot إن حلها هو نظام من ثلاث طبقات: طبقة إدخال تعليمات الحدث، وطبقة تنبؤ أساسية تستخدم تحسين Muon الموزع، واستراتيجية حزم متعددة الأحداث تدرب عدة أحداث داخل تسلسل طويل واحد.
وتفيد الشركة بأن النتائج تفوقت على Wan2.1-14B وOpen-Sora 2.0 في اختبارات توليد فيديو للذكاء المجسد، كما حققت إنجاز مهام أعلى من Pi0.5 وDreamZero في معيار Core15 L1 للروبوتات.
ما يجب مراقبته
الاختبار التالي هو ما إذا كان WALL-WM يستطيع الانتقال من أداء الاختبارات إلى سلوك روبوتي موثوق خارج العروض المضبوطة. ويشير المصدر إلى تحسن في جودة الحركة، والاتساق الدلالي، والمعقولية الفيزيائية، والاستدلال، والمناولة الدقيقة، ودرجات التعميم.
بالنسبة إلى مطوري الروبوتات، تكمن الإشارة الأكبر في أن الذكاء الاصطناعي المجسد ينتقل من التقليد البصري إلى التخطيط على مستوى الهدف. وإذا صمدت نماذج العالم القائمة على الأحداث في الاستخدام العملي، فقد تصبح أساسا أكثر ملاءمة للروبوتات التي تحتاج إلى التعامل مع أشياء وبيئات متغيرة.
Summary version for Medium
X-Square WALL-WM Points Robotics AI Toward Event-Level Planning
What the announcement means beyond the headline
Quick Summary: X-Square Robot released WALL-WM, an embodied AI world model that predicts semantic events rather than fixed motion frames. The company says the approach helps robots focus on task objectives such as grasping an object instead of memorizing pixel-level movement sequences.
The Architecture Signal
Most vision-language-action systems predict movement in small time slices. In the source example, a model may estimate where a robot hand should be at 0.1 seconds and 0.2 seconds, rather than reasoning directly about the target outcome.
Why Event Prediction Matters
The core promise is generalization.
- Point 1: The central topic is embodied AI, with the announcement framed around concrete operating detail.
- Point 2: A frame-based model can break when the cup, table, or timing changes because it has learned a narrow motion sequence.
The important shift is not the AI label, but the operating boundary it creates for teams.
Technical Proof Points
The WALL-WM paper identifies a mismatch among text, vision, and action data. Text carries high-level intent, vision changes continuously, and action is constrained by physics and contact.
Read the Full Deep Dive
Want to explore the complete technical analysis, enterprise trade-offs, and detailed metrics?
Read the full article originally published at SendTech Times